Data Preparation: #
The data consists of two experiments recorded in 2021. Time-lapse images of 24 well plate were recorded over 18 hours which yielded 70 9x9 tiled images per well. The plate was laid out such that 8 wells were stained with both Draq7 and HOECHST stain so they could be used for training. Each image was stitched together and segmented. Six wells were used to create the training and validation dataset.
Stitched images have dimensions of 2700 x 3600 pixels. The Unet model is dimensioned at 160 x 160 pixels.
Therefore, images are tiled in 160 x160 samples with 80-pixel strides. The tiled images were written to a HDF5 file in 1000 sample chunks. A segmented image label dataset was also written. Counts of the classes in each label image were recorded. Images that contained more than a single class were then extracted and written to a SSD drive using 1000 sample chunks.
The final dataset dimensions are:
Dataset Dimensions are (291765, 1, 160, 160)
Data Chunk Dimensions are (1000, 1, 160, 160)
Label Dimensions are (291765, 160, 160)
Label Chunk Dimensions are (1000, 160, 160)
The data was organized 100 sample batches and split into 2620 training batches and 290 validation batches. A roughly 90:10 train-test split. A single epoch was about 600 seconds when training two models with different hyperparameters.
Training Experiments Comparing Optimizers and Learning Rate Schedulers #
Compairing Adam and SGD optimizer. #
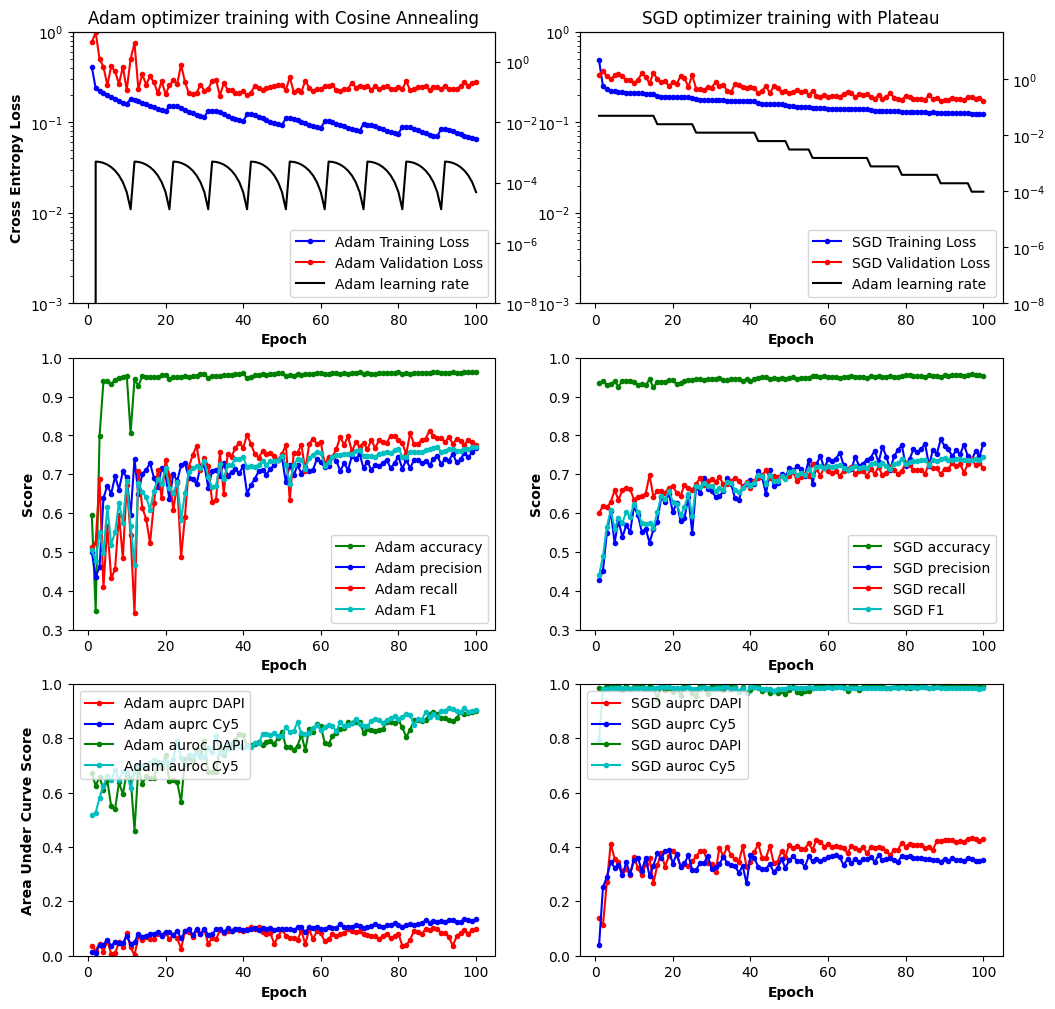
Comparison of Adam and Stochastic Gradient Descent. While Adam with Cosine Annealing had better training loss scores, the validation and precision-recal area under the curve scores were not better than Stocastic Gradient Descent with Reduced Learning Rate on Plataeu.
Previously, I had used Adam as an optimizer and had what I thought were good results. But when inspecting the images, the models were not predicting cell area or the DAPI and Cy5 channels well. I simplified the model to reduce the number of classes to 3: background, DAPI, and Cy5. I hoped that would improve training by reducing complexity of the model. I kept everything else the same and used cosine annealing with warm restarts because initially the loss values looked good. However when compairing more metrics such as precision and recall, Adam performed poorly compared to Stochastic Gradient Descent (SGD) with Reduced Learning Rate on Plateau. Over a weekend, I made a hybrid of the two learning rate schedulers though it still needs some tweaking.
Compairing Learning Rate Schedulers and Class Weights #
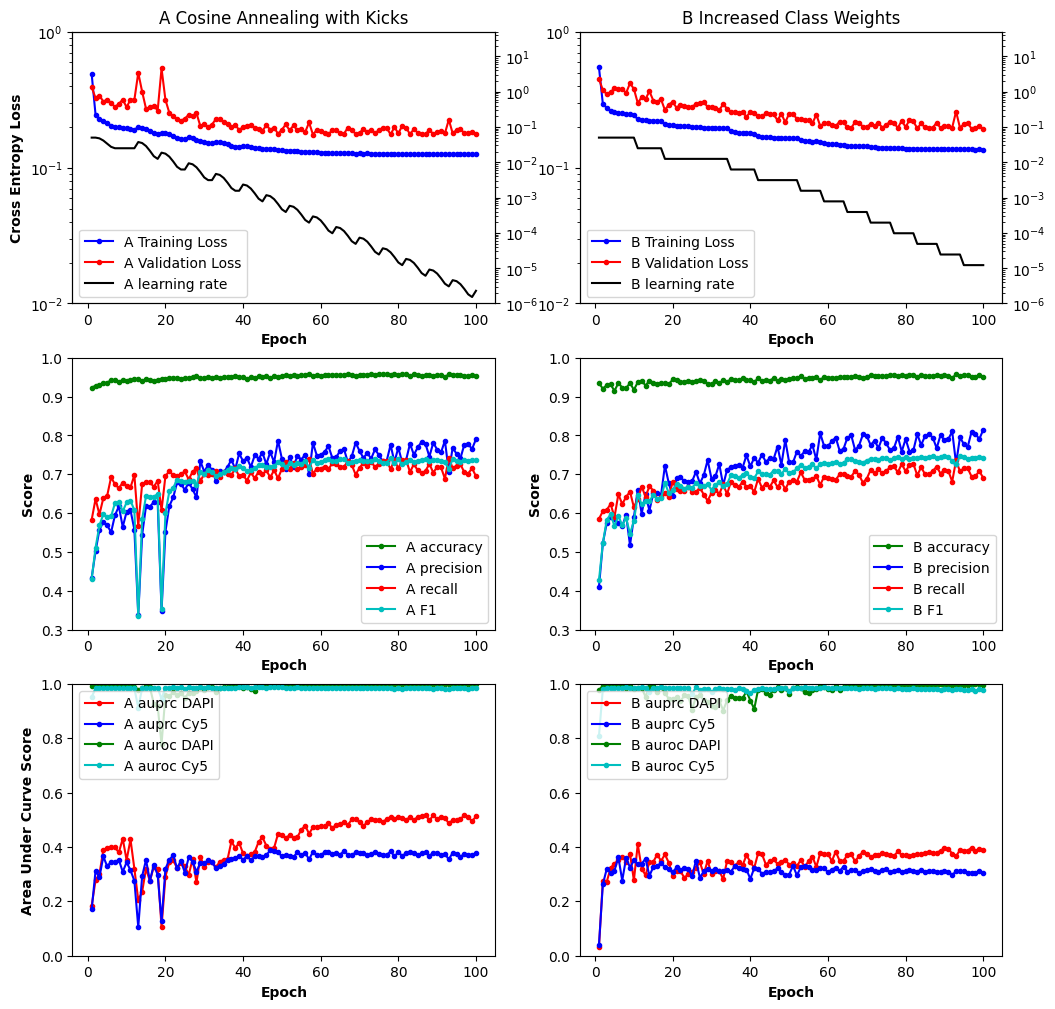
A combination of the learning rate schedules Cosine Annealing With Warm Restarts and Reduced Learning Rate on Plateau which I refer to here as Cosine Annealing with Kicks. The idea is that when the learning rate plateaus, the learning rate is kicked up by a percentage and then follows a cosine decay to a new minimum value.
The Cosine Annealing with Kicks seemed to provide slightly better results on the area under precision-recall curve for the DAPI (HOECHST) channel and similar results for the same measure of the Cy5 channel. Since the training loss and validation loss don’t appear to be diverging the model is still underfitting after 100 epochs.
Visualizing Classification During Training #
The above video shows how image classisifcation progresses with training over 100 epochs. True positive (TP) classifications are shown in green. False positives or False negatives (FP|FN) are shown in red or blue for the respective Cy5 or DAPI channel. After epoch 60 or so the model begins refining and the precision recal curves do tend move up and to the right indicating better performance.
This is a work in progress and will be updated as the project progresses.