Article Overview #
The TensorFlow tutorial this project is based on takes two neural networks, Mobilnetv2 and Pix2Pix and splices them together. While I really like the TensorFlow and Pix2Pix tutorials, the TensorFlow image segmentation tutorial lacked a description of the mechanics into how the models were built and consequently the steps to modify the models were a bit opaque. In particular, the example of adding skip connections to Mobilenetv2 was not clear. So part of this project was build up the networks layer by layer to replicate the TensorFlow image segmentation tutorial into Pytorch. The following is a description of building a U-net neural network using Mobilnetn2 as the network encoder and Pix2Pix the decoder network for segmenting images.
Unet architecture #
For a bit of background on neural networks, I highly suggest the video series by the YouTube channels 3Blue1Brown and Animated AI. The Animated AI is really quite good at explaining the ideas behind how 2D convolution is performed with different filters to create feature vectors that then are themselves used as inputs for additional convolutions. In addition, Animated AI has a really good explanation of the inverted bottleneck layer structure that is the basis of the Mobilenetv2 network topology.
Whenever someone writes about U-nets they always post the same picture from this paper. I will be no different here.
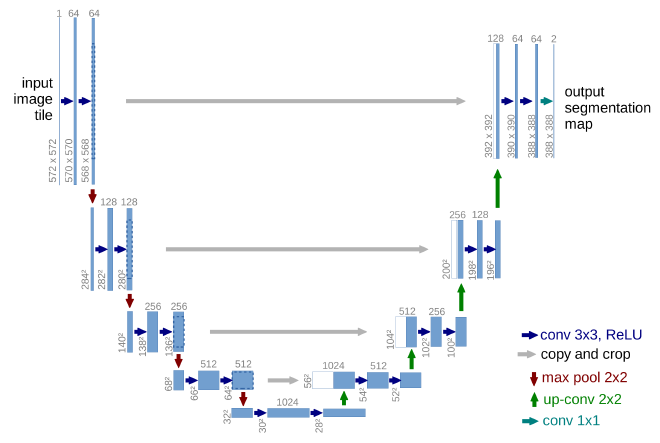
The idea of the U-net is that the network is split up into a encoder and a decoder sections. The encoder applies convolutions in steps that reduce the resolution at each of the steps but increases the feature depth. The decoder does the opposite as it takes feature vectors and then performs 2D transposed convolutions to take feature vectors and produces higher resolution but lower feature depth data. When the network is depicted, the network shape appears U-shaped when the encoder makes up the left side of the U-shape and decoder makes up the right side. Conceptually we also need to understand that the encoder side is transforming the images into a series of feature vectors that the decoder then uses to classify individual pixels.
Building up Mobilenetv2 with skip connections #
Mobilnetv2 is the second iteration of a neural network designed to reduce the number of variables and increase the overall speed and performance of image classification networks. The goal was to fit a complete neural network on small mobile devices like mobile phones. To achieve this goal, researchers were trying to optimize how to make the 2D convolutional steps more efficient. They increased efficiency of the 2D convolution by separating the process into two steps termed point-wise convolutions followed by a depth wise convolution. (This strategy is amazingly explained in the Animated AI video ). The set of convolutional operations are broken down into essentially three sets of operations and are described as point wise expansion convolution, depth wise convolution and a projection convolution. The convolutional blocks are termed as Inverted Residual blocks and are defined in the following code:
nn.Sequential(
# pointwise expansion convolution
nn.Conv2d(in_channels = inp, out_channels = hidden_dim, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# depthwise 3x3 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = hidden_dim, kernel_size = 3, stride = stride, padding = 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# projection 1x1 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = oup, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = oup, eps = 1e-3, momentum = 0.999),
)
Pytorch has Sequential layers which basically are a organizational tool to group a series of operations together and apply the output of the pervious operation or layer to the input of the next operation or layer. In this case a 2D convolution is applied to an input the dimensions of the input only matter according to the number of channels that are input and output as that with kernel_size and padding describe the dimension of the convolutional filters. Between each convolution are batch normalizations and a rectilinear function. The batch normalization helps prevent values from running away, and the rectilinear function is the activation function that scales the outputs between convolutions in a controlled way. RelU6 is a specific function that if the convolution outputs a value below zero, the RelU6 function just returns zero, but if it returns a positive value, the value is rescaled up to a maximum of the value of 6. These steps are a pointwise convolution followed by depth wise convolution followed by the pointwise projection convolution, with batch normalization after each convolution step and rectilinear scaling between the convolutions.
import torch.nn as nn
class InvertedResidual(nn.Module):
'''
Inverted Residual Block for Mobilen=net v2
Arg:
inp: number of input planes
oup: number of output planes or convolutional filters
kernel_size: nxn size of the convolutional kernel filters
stride: defualts to 2 as per tensorflow example
expand_ratio: increases the number of convolutional filters.
'''
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# depthwise convolution without expansion
nn.Conv2d(in_channels = hidden_dim, out_channels = hidden_dim, kernel_size = 3, stride = stride, padding = 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# pointwise-linear projection 1x1 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = oup, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = oup, eps = 1e-3, momentum = 0.999),
)
else:
self.conv = nn.Sequential(
# pointwise expansion convolution
nn.Conv2d(in_channels = inp, out_channels = hidden_dim, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# depthwise 3x3 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = hidden_dim, kernel_size = 3, stride = stride, padding = 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# projection 1x1 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = oup, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = oup, eps = 1e-3, momentum = 0.999),
)
Please note, I am not the original author of this code though I did modify it for readability.
Adding skip connections #
Skip connections are used in many deep convolutional neural networks because they can help increase the learning rates of layers that are buried deep within the networks. The idea is that layers that are located far within the network, the backpropagation steps reduce the rate that consecutive layers “learn”. Adding in skip connections helps reduce the number of layers between the layers and the output layers where backpropagation perturbations to the network are originated. I personally look at skip connections in U-nets as adding context to the feature vectors during the up-sampling steps. Information from the higher resolution but lower feature depth sections of the encoder are used to give “context” to the more heavily processed but lower resolution features that flowing up through the decoder network. In this case, the skip connections are made from the inverted residual bottleneck expansion step so the large feature vectors from the pointwise expansion step seem to provide a large amount of information to the decoders for classification.
Many of the code examples use a list and the above InvertedResidual class to build up the encoder. This method is a elegant coding solution but the issue is that access to the layer outputs from sequential blocks aren’t readily accessible. The straightforward solution is to split the convolutional block into two sections and use the output of the first section to create the skip connections. Those blocks then appear as follows:
class InvertedResidual_Partial_A(nn.Module):
'''
First section of a split inverted residual block.
The block is split to expose ReLU6 output of the first pointwise expansion layer for a skip connection.
This section completes the inverted residual block when placed immediatly before InvertedRedidual_Partial_B
'''
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual_Partial_A, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.conv = nn.Sequential(
# pointwise 1x1 expansion convolution
nn.Conv2d(in_channels = inp, out_channels = hidden_dim, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
)
def forward(self, x):
return self.conv(x)
class InvertedResidual_Partial_B(nn.Module):
'''
The second section of a split inverted residual layer.
This section completes the inverted residual block when placed immediatly after InvertedRedidual_Partial_A
'''
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual_Partial_B, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.conv = nn.Sequential(
# depthwise 3x3 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = hidden_dim, kernel_size = 3, stride = stride, padding = 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(num_features = hidden_dim, eps = 1e-3, momentum = 0.999),
nn.ReLU6(inplace=False),
# projection 1x1 convolution
nn.Conv2d(in_channels = hidden_dim, out_channels = oup, kernel_size = 1, stride = 1, padding = 0, bias=False),
nn.BatchNorm2d(num_features = oup, eps = 1e-3, momentum = 0.999),
)
def forward(self, x):
return self.conv(x)
Pix2Pix Upsample Decoder Block #
class UpSample(nn.Module):
'''
Decoder Block from Pix2Pix
Upsamples input: Conv2DTranspose => Batchnorm +> Dropout => Relu
Arg:
inp: number of input planes
oup: number of output planes or convolutional filters
kernel_size: nxn size of the convolutional kernel filters
stride: defualts to 2 as per tensorflow example
padding: set as same to return the same size block.
dropout: include dropout layer on True
'''
def __init__(self, inp, oup, kernel_size = 3, stride = 2, padding = 1, dropout = False):
super(UpSample, self).__init__()
self.conv2dtrans = nn.ConvTranspose2d(in_channels = inp, out_channels = oup, kernel_size = kernel_size, stride = stride, padding = padding)
self.batchnorm2d = nn.BatchNorm2d(oup)
self.relu = nn.ReLU(inplace = True)
self.dropout = None
if dropout:
self.dropout = nn.Dropout2d(p = 0.5, inplace = True)
def forward(self, x):
fx = self.conv2dtrans(x)
fx = self.batchnorm2d(fx)
if self.dropout is not None:
fx = self.dropout(fx)
fx = self.relu(fx)
return fx
Organizing the Mobilnet Blocks #
The explicit definition of the blocks is given here for study. There may be other much more elegant methods for generating the network structure but sometimes a hard coded structure is beneficial from a learning and reading standpoint. Please note that MobileNet was designed to have RGB input images, but the microscopy images we have are just 16bit unsigned integers. There are two solutions to adapting the network input from the 3 input channels to the single image channel. The first is to replicate the images so that the correct data dimensions (mxmx3) are fed into the network. The dimensions are increased the x.repeat(1,3,1,1) statement in the forward function. The other option is sum across the 3rd dimension of the convolutional filters when loading the model weights. I don’t have the second method presented here but may add it in at a later date.
class Unet_MNv2(nn.Module):
'''
Encoder of MobileNet v2
Decoder Pix2Pix
Functions to generate the models were checked against the tensorflow code.
Args:
input_size = nxn dimensions of the input image
'''
def __init__(self, input_size=224, input_layers = 3, output_classes = 5):
super(Unet_MNv2, self).__init__()
invRes_block = InvertedResidual
invRes_block_A = InvertedResidual_Partial_A
invRes_block_B = InvertedResidual_Partial_B
decode_block = UpSample
input_channel = 32
interverted_residual_setting = [
# t = expansion factor?
# c = convolutional filters or output channels
# n = repeated blocks per layer
# s = stride
# t, c, n, s
[1, 16, 1, 1], # blk0 expansion block
[6, 24, 2, 2], # blk 1-2
[6, 32, 3, 2], # blk 3-5
[6, 64, 4, 2], # blk 6-9
[6, 96, 3, 1], # blk 10-12
[6, 160, 3, 2], # blk 13-15
[6, 320, 1, 1], # blk 16
]
# featurs is the list of layers in the model?
# Conv2d then batch2dnorm then Relu6 stride 2 reduces input size by 1/2 input eg 128 x 128 to 64 x 64
self.encoder_input = conv_bneck(input_layers, 32, 2)
# Expand Convolutional block Special case
self.encoder_blk00 = invRes_block(inp = 32, oup = 16, stride = 1, expand_ratio = 1)
# get 'block_1_expand_relu' skip connection 96x64x64 to decode_blk04
self.encoder_blk01_ReLu = invRes_block_A(inp = 16, oup = 24, stride = 2, expand_ratio = 6)
# stride 2 reduces input size by 1/4 input eg 128 x 128 to 32 x 32
self.encoder_blk01_DwPr = invRes_block_B(inp = 16, oup = 24, stride = 2, expand_ratio = 6)
self.encoder_blk02 = invRes_block(inp = 24, oup = 24, stride = 1, expand_ratio = 6)
# get 'block_3_expand_relu' skip connection 144x32x32 to decode_blk03
self.encoder_blk03_ReLu = invRes_block_A(inp = 24, oup = 32, stride = 2, expand_ratio = 6)
# stride 2 reduces input size by 1/8 input eq 128 x128 to 16 x 16
self.encoder_blk03_DwPr = invRes_block_B(inp = 24, oup = 32, stride = 2, expand_ratio = 6)
self.encoder_blk04 = invRes_block(inp = 32, oup = 32, stride = 1, expand_ratio = 6)
self.encoder_blk05 = invRes_block(inp = 32, oup = 32, stride = 1, expand_ratio = 6)
# get 'block_6_expand_relu' skip connection 192x16x16 skip to to decode blk02
self.encoder_blk06_ReLu = invRes_block_A(inp = 32, oup = 64, stride = 2, expand_ratio = 6)
# stride 2 reduces input size by 1/16 input eg 128 x 128 to 8 x 8
self.encoder_blk06_DwPr = invRes_block_B(inp = 32, oup = 64, stride = 2, expand_ratio = 6)
self.encoder_blk07 = invRes_block(inp = 64, oup = 64, stride = 1, expand_ratio = 6)
self.encoder_blk08 = invRes_block(inp = 64, oup = 64, stride = 1, expand_ratio = 6)
self.encoder_blk09 = invRes_block(inp = 64, oup = 64, stride = 1, expand_ratio = 6)
self.encoder_blk10 = invRes_block(inp = 64, oup = 96, stride = 1, expand_ratio = 6)
self.encoder_blk11 = invRes_block(inp = 96, oup = 96, stride = 1, expand_ratio = 6)
self.encoder_blk12 = invRes_block(inp = 96, oup = 96, stride = 1, expand_ratio = 6)
# get 'block_13_expand_relu' skip connection of dim 576x8x8 to decode blk01
self.encoder_blk13_ReLu = invRes_block_A(inp = 96, oup = 160, stride = 2, expand_ratio = 6)
# stride 2 reduces input size by 1/32 input 128 x 128 to 4 x 4
self.encoder_blk13_DwPr = invRes_block_B(inp = 96, oup = 160, stride = 2, expand_ratio = 6)
self.encoder_blk14 = invRes_block(inp = 160, oup = 160, stride = 1, expand_ratio = 6)
self.encoder_blk15 = invRes_block(inp = 160, oup = 160, stride = 1, expand_ratio = 6)
# get 'block_16_project' skip connection as output to Decoder blk01 320x4x4
self.encoder_blk16 = invRes_block(inp = 160, oup = 320, stride = 1, expand_ratio = 6)
# input channels include conncatination of skip connection outputs.
# convtranspose2d with stride of 2 should give a input 320x4x4 to 512x8x8
self.decoder_blk01 = decode_block(inp = 320, oup = 512, kernel_size = 4, stride = 2, padding = 1, dropout = False)
# concatinate 512x8x8 from decoder_blk01 and 576x8x8 from reLu_blk13 for 1088x8x8 input
# convtranspose2d with stride of 2concat output should be 1088x8x8 output 256x16x16
self.decoder_blk02 = decode_block(inp = 512+576, oup = 256, kernel_size = 4, stride = 2, padding = 1, dropout = False)
# concatinate 256x16x16from decoder_blk02 and 192x16x16 from reLu_blk06 for 448x16x16 input
# convtranspose2d with a stride of 2 the input should be 448x16x16 output 128x32x32
self.decoder_blk03 = decode_block(inp = 256+192, oup = 128, kernel_size = 4, stride = 2, padding = 1, dropout = False)
# concatinate 128x32x32 from decoder_blk03 and 144x32x32 from reLu_blk03 for 272x32x32 input
# convtranspose2d with stride of 2 the input should be 272x32x32 output 64x64x64
self.decoder_blk04 = decode_block(inp = 128+144, oup = 64, kernel_size = 4, stride = 2, padding = 1, dropout = False)
# concatinate 64x64x64 from decoder_blk04 and 96x64x64 from reLu_blk01 for 160x64x64 input
# convtranspose2d with stride of 2 the input should be 160x64x64 output number of classesx128x128
# final upscaling to 64x64 to the input image hypothetically 128x128
self.decoder_2dTrp = nn.ConvTranspose2d(in_channels = 64+96, out_channels = output_classes, kernel_size = 4, stride = 2, padding = 1)
self._initialize_weights()
def forward(self, x):
e_inp = self.encoder_input(x.repeat(1,3,1,1))
e00 = self.encoder_blk00(e_inp)
e01_ReLu = self.encoder_blk01_ReLu(e00)
e01 = self.encoder_blk01_DwPr(e01_ReLu)
e02 = self.encoder_blk02(e01)
e03_ReLu = self.encoder_blk03_ReLu(e02)
e03 = self.encoder_blk03_DwPr(e03_ReLu)
e04 = self.encoder_blk04(e03)
e05 = self.encoder_blk05(e04)
e06_ReLu = self.encoder_blk06_ReLu(e05)
e06 = self.encoder_blk06_DwPr(e06_ReLu)
e07 = self.encoder_blk07(e06)
e08 = self.encoder_blk08(e07)
e09 = self.encoder_blk09(e08)
e10 = self.encoder_blk10(e09)
e11 = self.encoder_blk11(e10)
e12 = self.encoder_blk12(e11)
e13_ReLu = self.encoder_blk13_ReLu(e12)
e13 = self.encoder_blk13_DwPr(e13_ReLu)
e14 = self.encoder_blk14(e13)
e15 = self.encoder_blk15(e14)
e16 = self.encoder_blk16(e15) #320x4x4
d01 = self.decoder_blk01(e16)
# concatinate 512x8x8 from decoder_blk01 and
# 576x8x8 from reLu_blk13 for 1088x8x8 input
cat01 = torch.cat((d01, e13_ReLu), dim = 1)
d02 = self.decoder_blk02(cat01)
# concatinate 256x16x16from decoder_blk02 and
# 192x16x16 from reLu_blk06 for 448x16x16 input
cat02 = torch.cat((d02, e06_ReLu), dim = 1)
d03 = self.decoder_blk03(cat02)
# concatinate 128x32x32 from decoder_blk03
# and 144x32x32 from reLu_blk03 for 272x32x32 input
cat03 = torch.cat((d03, e03_ReLu), dim = 1)
d04 = self.decoder_blk04(cat03)
# concatinate 64x64x64 from decoder_blk04
# and 96x64x64 from reLu_blk01 for 160x64x64 input
cat04 = torch.cat((d04, e01_ReLu), dim = 1)
out = self.decoder_2dTrp(cat04)
return out
Importing Imagenet Weights the hacky way #
Download the weights for Imagenet. The name of the file is: “mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.hdf5”
Next we need to load the hdf5 file as a dictionary and find the layers. I have a hdf5 loader that I use as a utility function in the ODELAY package.
Then write out a list of layers and line them up. The following script works to take the Mobilnetv2 definintion above and in the tensorflow weights.
def add_imagenet_weights(self, weights_path = None, requires_grad: bool = False):
if weights_path is None:
weights_path = pathlib.Path("E:/MAc 2021-03-25 Exp v1 Data/PyTorch_2024-10-23/Keras_Mobilenetv2_Weights/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.hdf5")
tf2_mobilenetv2_weights = fio.loadData(weights_path)
if requires_grad is None:
requires_grad = False
# t = expansion factor?
# c = convolutional filters or output channels
# n = repeated blocks per layer
# s = stride
# t, c, n, s
MNv2_layers = [[1, 16, 1, 1], # blk0 expansion block
[6, 24, 2, 2], # blk 1-2
[6, 32, 3, 2], # blk 3-5
[6, 64, 4, 2], # blk 6-9
[6, 96, 3, 1], # blk 10-12
[6, 160, 3, 2], # blk 13-15
[6, 320, 1, 1], # blk 16
]
blk = 0
btlnk_layer_names = ['Conv1','bn_Conv1-weight', 'bn_Conv1-bias']
for t,c,n,s in MNv2_layers:
for i in range(n):
if t == 1:
seq_layers = [ f'mobl{blk}_conv_{blk}_depthwise',
f'bn{blk}_conv_{blk}_bn_depthwise-weight',
f'bn{blk}_conv_{blk}_bn_depthwise-bias',
f'mobl{blk}_conv_{blk}_project',
f'bn{blk}_conv_{blk}_bn_project-weight',
f'bn{blk}_conv_{blk}_bn_project-bias']
else:
seq_layers = [ f'mobl{blk}_conv_{blk}_expand',
f'bn{blk}_conv_{blk}_bn_expand-weight',
f'bn{blk}_conv_{blk}_bn_expand-bias',
f'mobl{blk}_conv_{blk}_depthwise',
f'bn{blk}_conv_{blk}_bn_depthwise-weight',
f'bn{blk}_conv_{blk}_bn_depthwise-bias',
f'mobl{blk}_conv_{blk}_project',
f'bn{blk}_conv_{blk}_bn_project-weight',
f'bn{blk}_conv_{blk}_bn_project-bias']
btlnk_layer_names += seq_layers
blk+=1
batch_norm = {'weight': 'beta:0', 'bias':'gamma:0'}
model_state_dict = self.state_dict()
mobilnet_weights = {}
for (name, py_param), layer_name in zip(self.named_parameters(), btlnk_layer_names):
name2 = 'weight'
split_name = layer_name.split('-')
if len(split_name)==2:
tf_param = tf2_mobilenetv2_weights[split_name[0]][split_name[0]][batch_norm[split_name[1]]]
model_state_dict[name] = torch.from_numpy(tf_param.astype('float32'))
model_state_dict[name].requires_grad = requires_grad
else:
if split_name[0].split('_')[-1] == 'depthwise':
tf_param = tf2_mobilenetv2_weights[split_name[0]][split_name[0]]['depthwise_kernel:0']
tf_param = np.transpose(tf_param, axes = (2,3,0,1))
model_state_dict[name] = torch.from_numpy(tf_param.astype('float32'))
model_state_dict[name].requires_grad = requires_grad
else:
tf_param = tf2_mobilenetv2_weights[split_name[0]][split_name[0]]['kernel:0']
tf_param = np.transpose(tf_param, axes = (3,2,0,1))
model_state_dict[name] = torch.from_numpy(tf_param.astype('float32'))
model_state_dict[name].requires_grad = requires_grad
self.load_state_dict(model_state_dict)
# Set layers for freezeing.
# Remeber to add code filter(lambdailter(lambda p: p.requires_grad, mode.parameters())
# to the optimizer otherwise the weights will still be changed.
for name, param in self.named_parameters():
if name.split('_')[0] == 'encoder':
param.requires_grad = requires_grad
return None